Securing AWS EKS: Implementing Least-Privilege Access with IRSA
Rewanth Tammana is a security ninja, open-source contributor, and a full-time freelancer. Previously, Senior Security Architect at Emirates NBD (National Bank of Dubai). He is passionate about DevSecOps, Cloud, and Container Security. He added 17,000+ lines of code to Nmap (famous as Swiss Army knife of network utilities). Holds industry certifications like CKS (Certified Kubernetes Security Specialist), CKA (Certified Kubernetes Administrator), etc.
Rewanth speaks and delivers training at international security conferences worldwide including Black Hat, Defcon, Hack In The Box (Dubai and Amsterdam), CRESTCon UK, PHDays, Nullcon, Bsides, CISO Platform, null chapters and multiple others.
He was recognized as one of the MVP researchers on Bugcrowd (2018) and identified vulnerabilities in several organizations. He also published an IEEE research paper on an offensive attack in Machine Learning and Security. He was also a part of the renowned Google Summer of Code program.
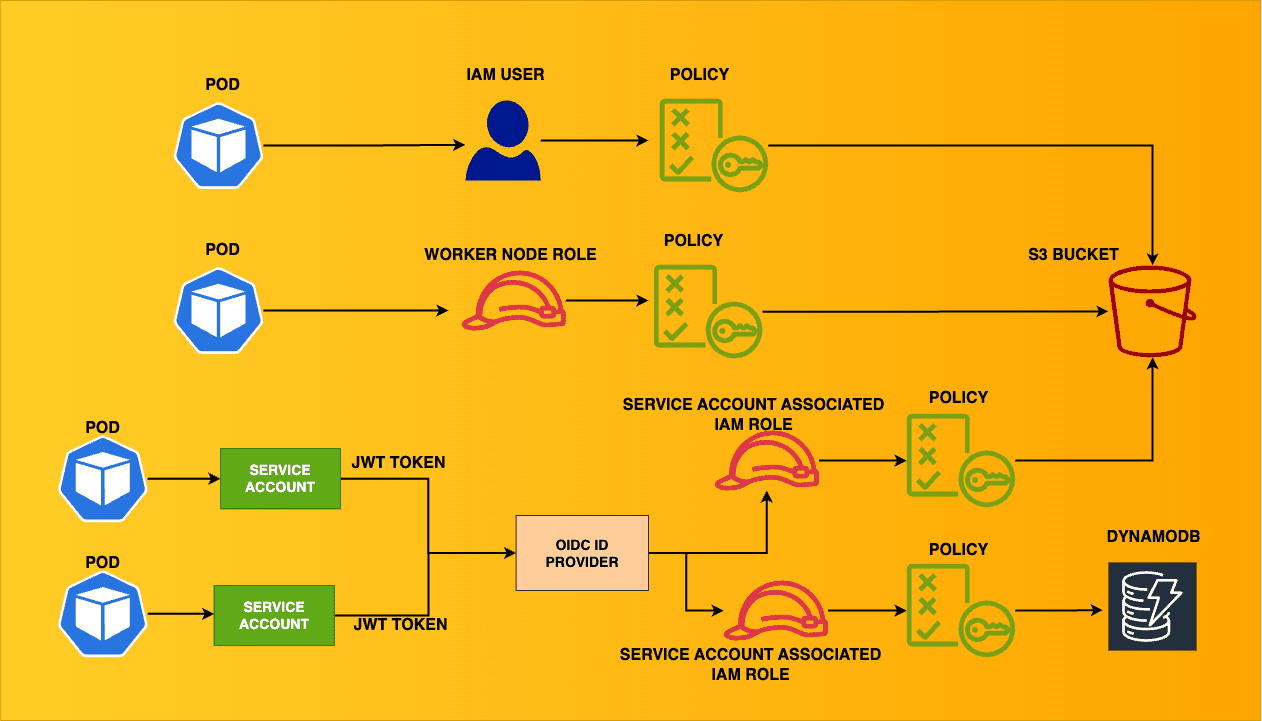
Ensuring least-privilege access in Kubernetes can be complex at times for security & DevOps teams. This blog aims to cover a variety of scenarios where the EKS cluster connects with other AWS resources. This is the architecture of the multiple scenarios we will build.
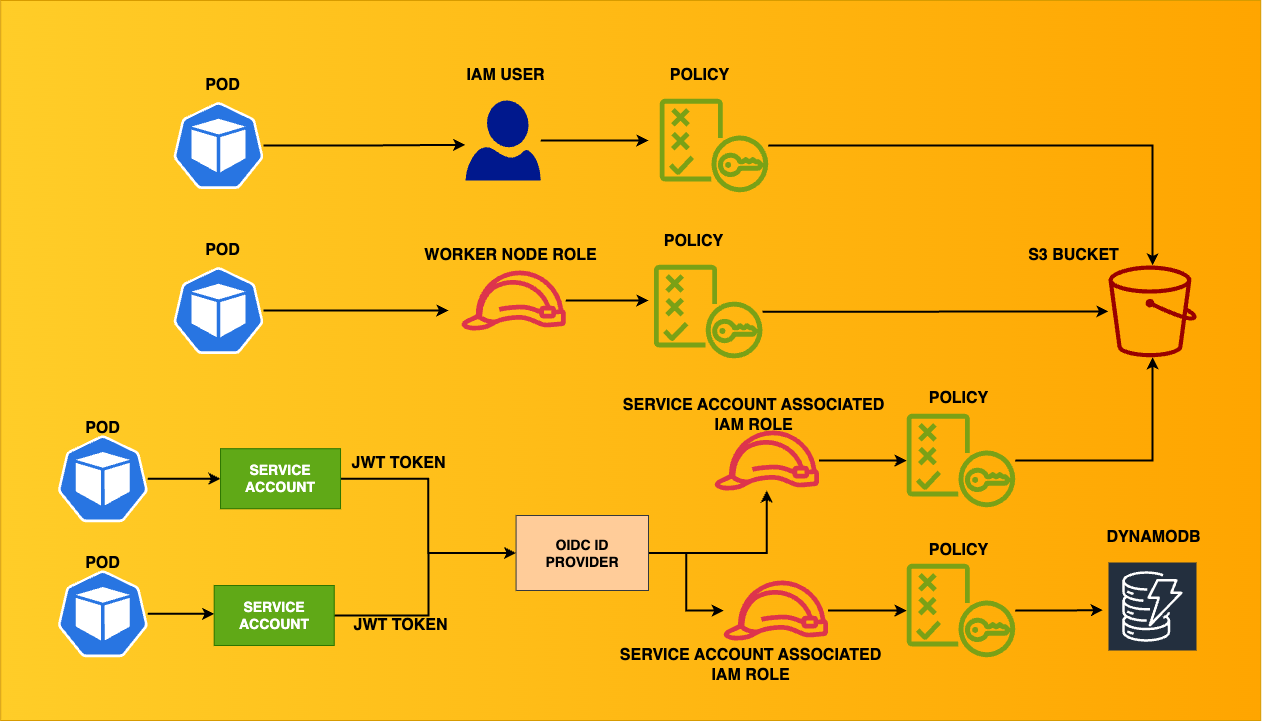
Different ways to connect with AWS services:
Using IAM User Credentials through Environment Variables
Assign permissions to the EKS worker nodes
IAM Roles for Service Accounts (IRSA)
Prerequisites
Before getting started, a few terminologies to get familiar with.
IRSA refers to "IAM Roles for Service Accounts".
OpenID Connect (OIDC) identity provider is a service in AWS that allows you to manage identity federation and user identities in a scalable and secure way. In the context of Amazon EKS, OIDC is used to associate IAM roles with Kubernetes service accounts. This allows Kubernetes pods to have specific IAM roles, providing a secure and fine-grained way to grant AWS permissions to pods.
Scenario
Assume we have an application that fetches random images from the internet every 30 seconds, & uploads them to an s3 bucket.
To deploy this application, the primary requirement is to enable the application to authenticate with the S3 bucket and push images.
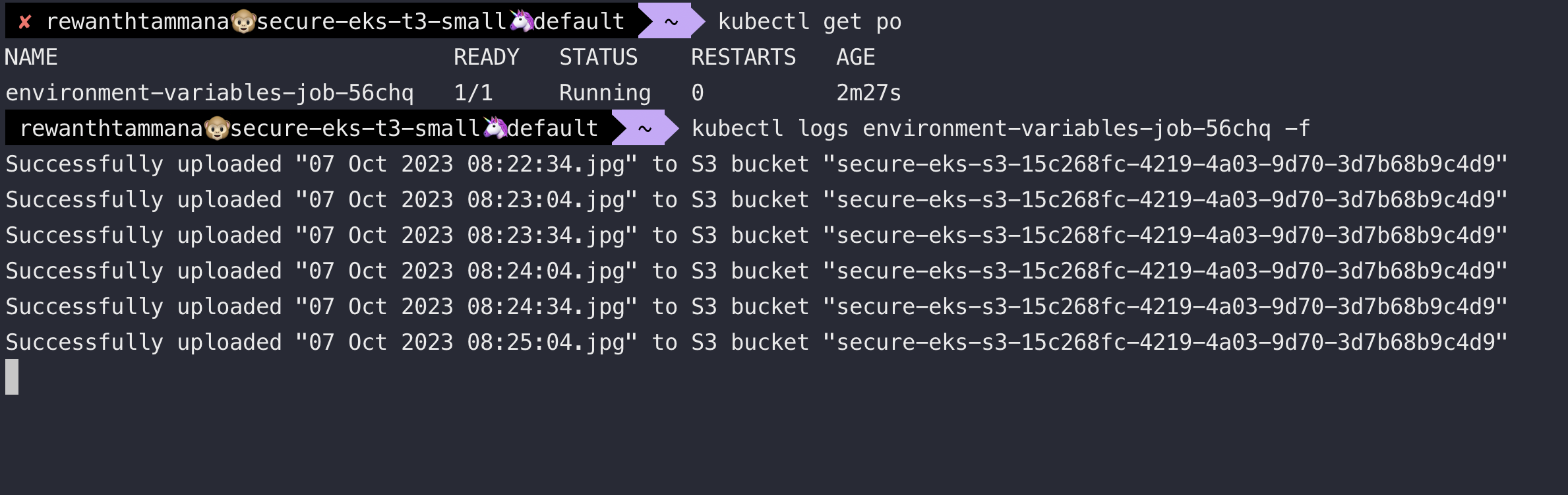
The code is available here. If you want to build your image or use the existing ones.
IMAGE=rewanthtammana/secure-eks:v1
git clone https://github.com/rewanthtammana/secure-eks
cd secure-eks/least-privilege-access
docker build -t $IMAGE .
docker push $IMAGE
Create required AWS resources
Change AWS CLI Output from Vim to Terminal
export AWS_PAGER=
EKS cluster
Make sure to have a cluster. If you don't, create one.
export cluster_name=secure-eks
eksctl create cluster $cluster_name -M 1 -m 1 --ssh-access
Create s3 bucket
export bucket_name=secure-eks-s3-$(uuidgen | tr '[:upper:]' '[:lower:]')
aws s3api create-bucket --bucket $bucket_name
echo "Created bucket: $bucket_name"
Create a policy to allow write operations to this S3 bucket
echo "{
\"Version\": \"2012-10-17\",
\"Statement\": [
{
\"Effect\": \"Allow\",
\"Action\": [
\"s3:PutObject\"
],
\"Resource\": [
\"arn:aws:s3:::$bucket_name/*\"
]
}
]
}" > s3-$bucket_name-access.json
export policy_name=secure-eks-s3-write-policy
export create_policy_output=$(aws iam create-policy --policy-name $policy_name --policy-document file://s3-$bucket_name-access.json)
export policy_arn=$(echo $create_policy_output | jq -r '.Policy.Arn')
Using IAM User Credentials through Environment Variables
Now, we have the cluster & S3 bucket. To ensure our application can connect with the S3 bucket, we need to create an IAM user with permission to access our s3 bucket.
Create IAM user
export iam_user=secure-eks-iam-user
aws iam create-user --user-name $iam_user
Attach the policy to the IAM user
aws iam attach-user-policy --user-name $iam_user --policy-arn $policy_arn
Create access & secret key for IAM user
export results=$(aws iam create-access-key --user-name $iam_user)
export access_key=$(echo $results | jq -r '.AccessKey.AccessKeyId')
export secret_key=$(echo $results | jq -r '.AccessKey.SecretAccessKey')
echo "Access Key: $access_key"
echo "Secret Key: $secret_key"
Create Kubernetes Job
With the above information of access & secret key, we can allow our application to connect with a specific s3 bucket.
echo "apiVersion: batch/v1
kind: Job
metadata:
name: environment-variables-job
spec:
template:
spec:
containers:
- name: environment-variables-container
image: rewanthtammana/secure-eks:v1
env:
- name: AWS_REGION
value: us-east-1
- name: AWS_ACCESS_KEY
value: $access_key
- name: AWS_SECRET_KEY
value: $secret_key
- name: S3_BUCKET_NAME
value: $bucket_name
restartPolicy: Never" | kubectl apply -f-
Summary
We successfully connected our application with the AWS S3 bucket to push its images. But from an operational & security standpoint, this isn't the best approach.
It's complex to maintain, rotate & secure these credentials from leaking.
What if someone gets their hand on the authentication details?
What if they use it to exfiltrate the data?
What if they use it to manipulate the information?
How to differentiate b/w legitimate & malicious requests?
A lot of questions pop up & it ain't pretty. We will discuss alternate & better ways to accomplish the goal in the following sections.
Cleanup
Delete the resources before proceeding to next section
aws iam detach-user-policy --user-name $iam_user --policy-arn $policy_arn
aws iam delete-access-key --access-key-id $access_key --user $iam_user
aws iam delete-user --user-name $iam_user
Assign permissions to the EKS worker nodes
In the above scenario, we learned that it's challenging to secure and rotate the access keys, etc. An alternative approach would be to assign permissions to the EKS worker nodes to access the s3 bucket.
Get EKS worker node ARN
In this case, we created a single-node cluster, so we have only one worker node.
eks_worker_node_role_name=$(eksctl get nodegroup --cluster $cluster_name -o json | jq -r '.[].NodeInstanceRoleARN' | cut -d '/' -f 2)
Attach the policy to the EKS worker node role
aws iam attach-role-policy --role-name $eks_worker_node_role_name --policy-arn $policy_arn
Create Kubernetes Job
Make sure you have the bucket_name environment variable.
echo "apiVersion: batch/v1
kind: Job
metadata:
name: environment-variables-job
spec:
template:
spec:
containers:
- name: environment-variables-container
image: rewanthtammana/secure-eks:ok-amd64
env:
- name: AWS_REGION
value: us-east-1
- name: S3_BUCKET_NAME
value: $bucket_name
restartPolicy: Never" | kubectl apply -f-
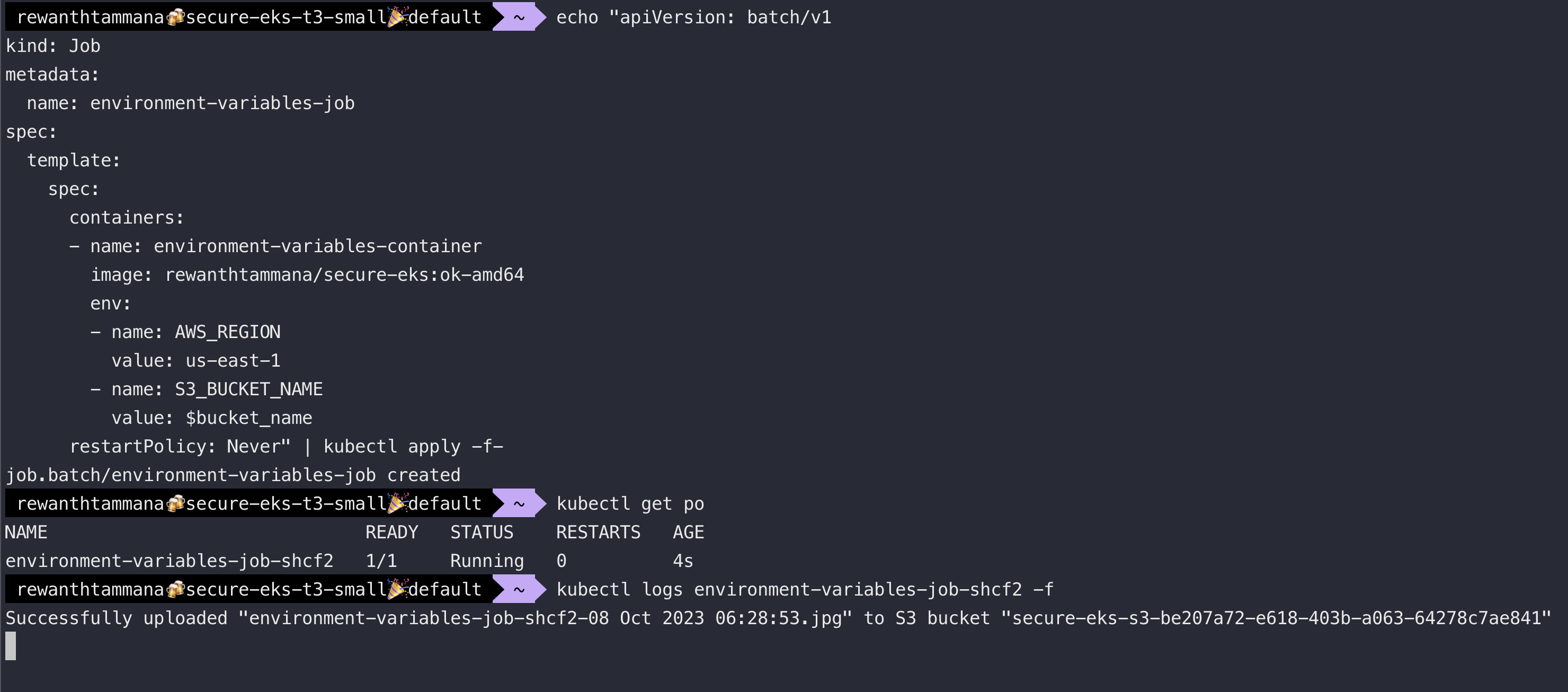
Summary
This is better than the previous method but the issue with this approach is that any pod created on this node will have excessive permissions, in this case, S3 bucket push permissions violating the least privilege principle. To overcome these risks, we will use IRSA.
Cleanup
Detach the role policy before proceeding to next section
aws iam detach-role-policy --role-name $eks_worker_node_role_name --policy-arn $policy_arn
IAM Roles for Service Accounts (IRSA)
Check if the IAM OpenID Connect provider status
eksctl get cluster $cluster_name -ojson | jq -r '.[].Tags["alpha.eksctl.io/cluster-oidc-enabled"]'
Create IAM OpenID Connect provider
If it's not enabled, enable it
eksctl utils associate-iam-oidc-provider --cluster $cluster_name --approve
Create a policy to allow access to the S3 bucket
echo "{
\"Version\": \"2012-10-17\",
\"Statement\": [
{
\"Effect\": \"Allow\",
\"Action\": [
\"s3:PutObject\"
],
\"Resource\": [
\"arn:aws:s3:::$bucket_name/*\"
]
}
]
}" > s3-$bucket_name-access.json
export policy_name=secure-eks-s3-write-policy
export create_policy_output=$(aws iam create-policy --policy-name $policy_name --policy-document file://s3-$bucket_name-access.json)
export policy_arn=$(echo $create_policy_output | jq -r '.Policy.Arn')
Create an IAM service account with the above policy
eks_service_account=s3-write-service-account
eksctl create iamserviceaccount --name $eks_service_account --namespace default --cluster $cluster_name --attach-policy-arn $policy_arn --approve
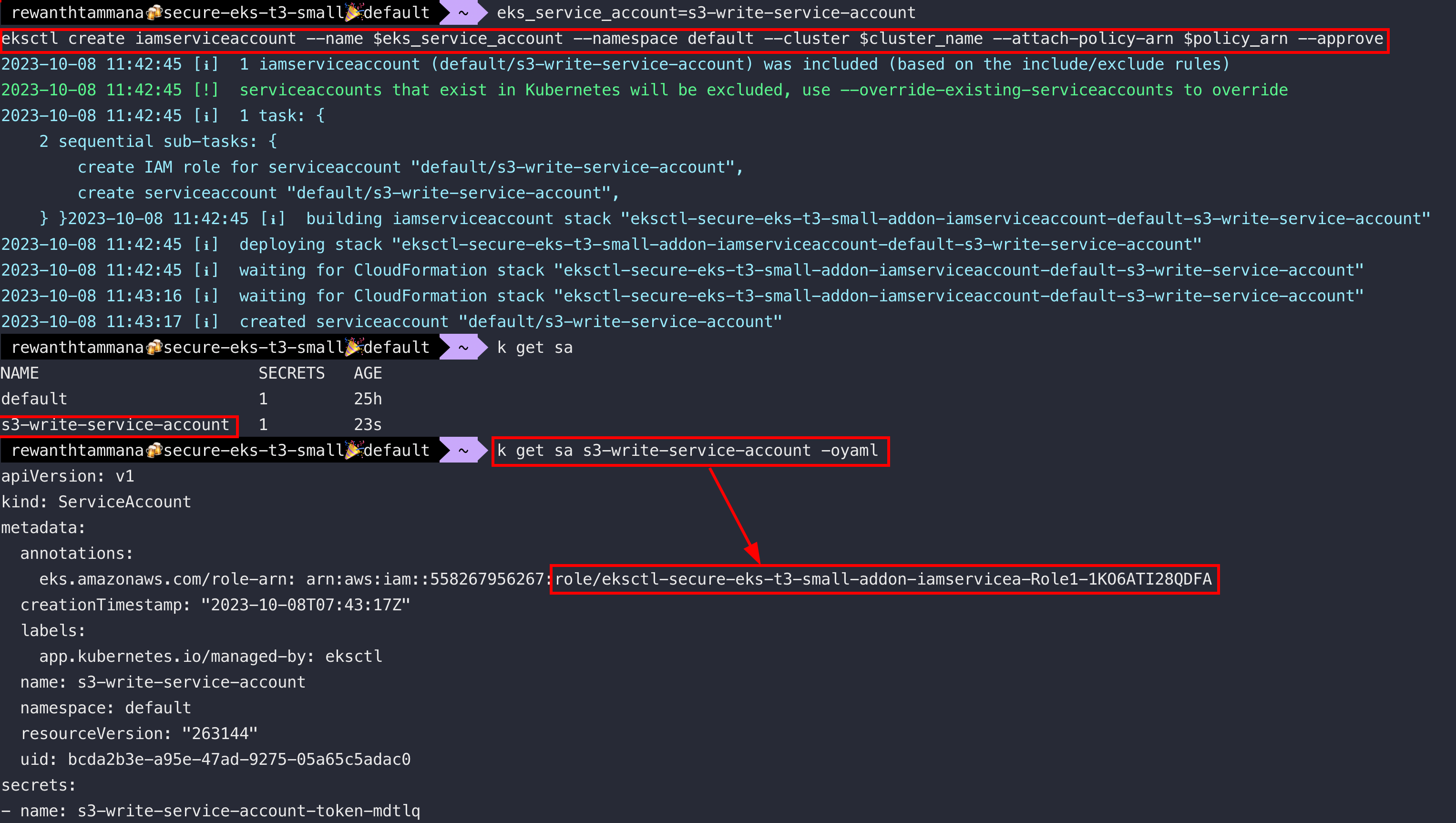
Create Kubernetes Job
echo "apiVersion: batch/v1
kind: Job
metadata:
name: environment-variables-job
spec:
template:
spec:
serviceAccountName: $eks_service_account
containers:
- name: environment-variables-container
image: rewanthtammana/secure-eks:ok-amd64
env:
- name: AWS_REGION
value: us-east-1
- name: S3_BUCKET_NAME
value: $bucket_name
restartPolicy: Never" | kubectl apply -f-
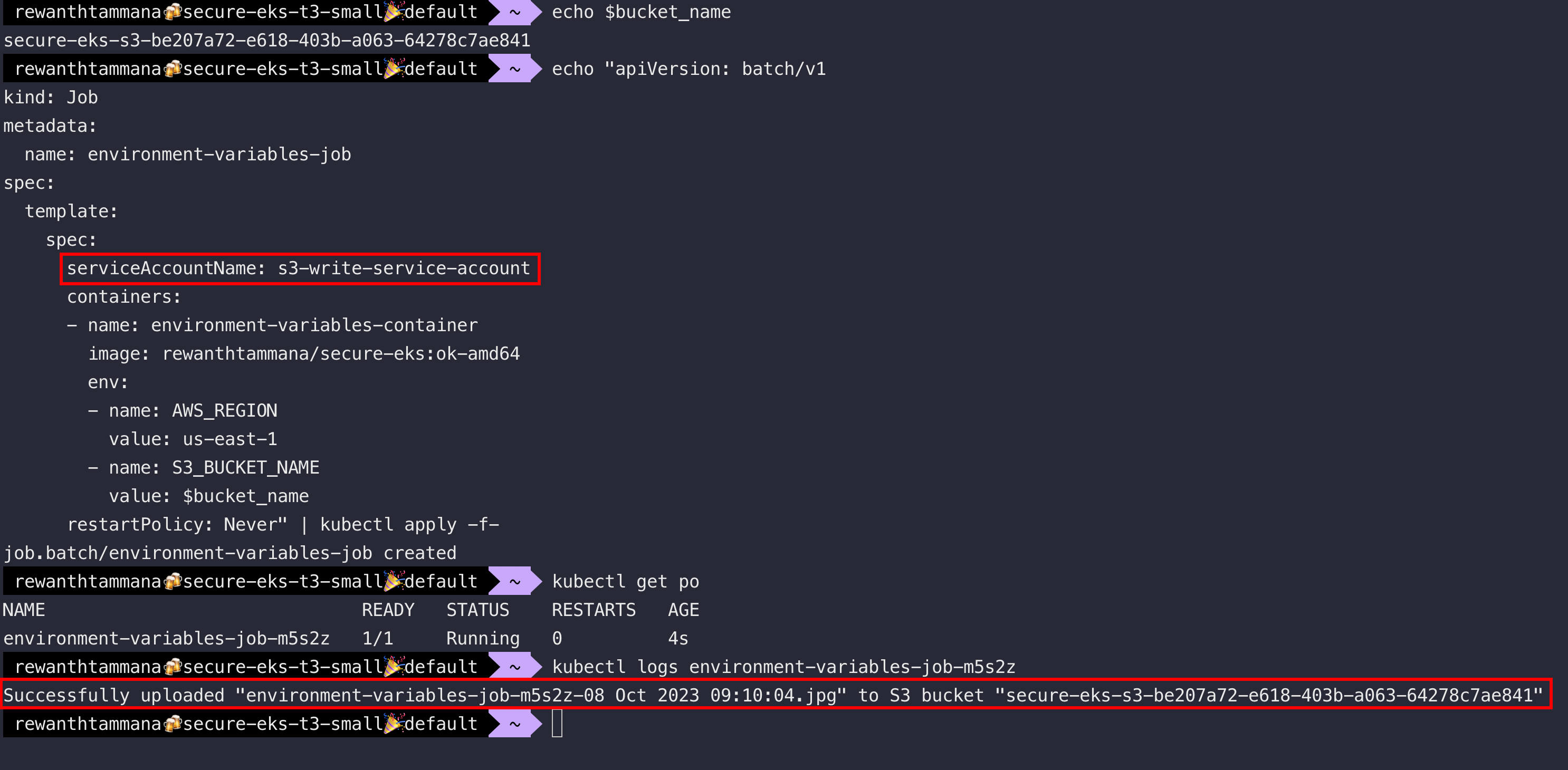
CloudFormation, JWT, X509 & more
Examine CloudFormation of IAM service account creation
If we observe the above output, CloudFormation was used to create the required resources. Let's have a look at CloudFormation to see a list of created resources.
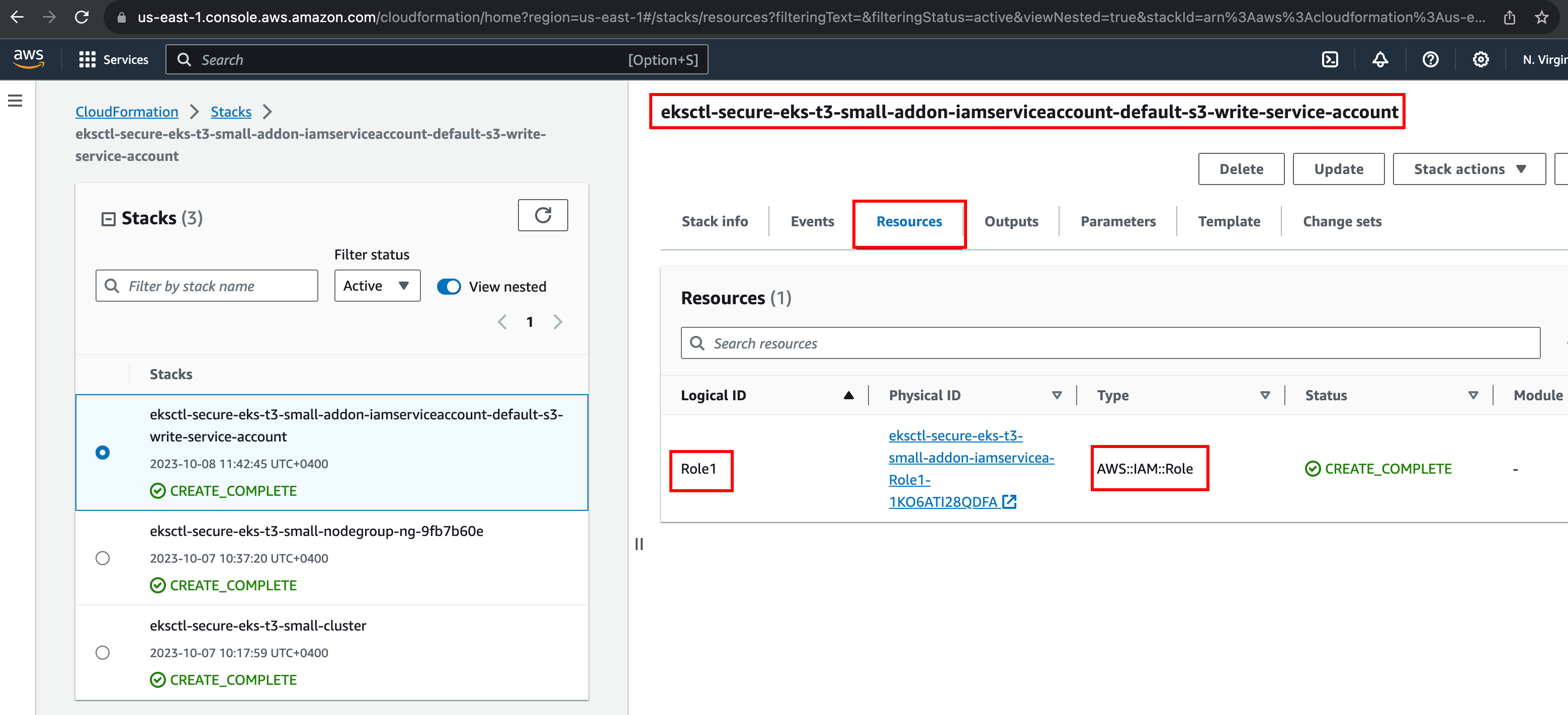
Click on the "Physical ID" link to look at the role permissions
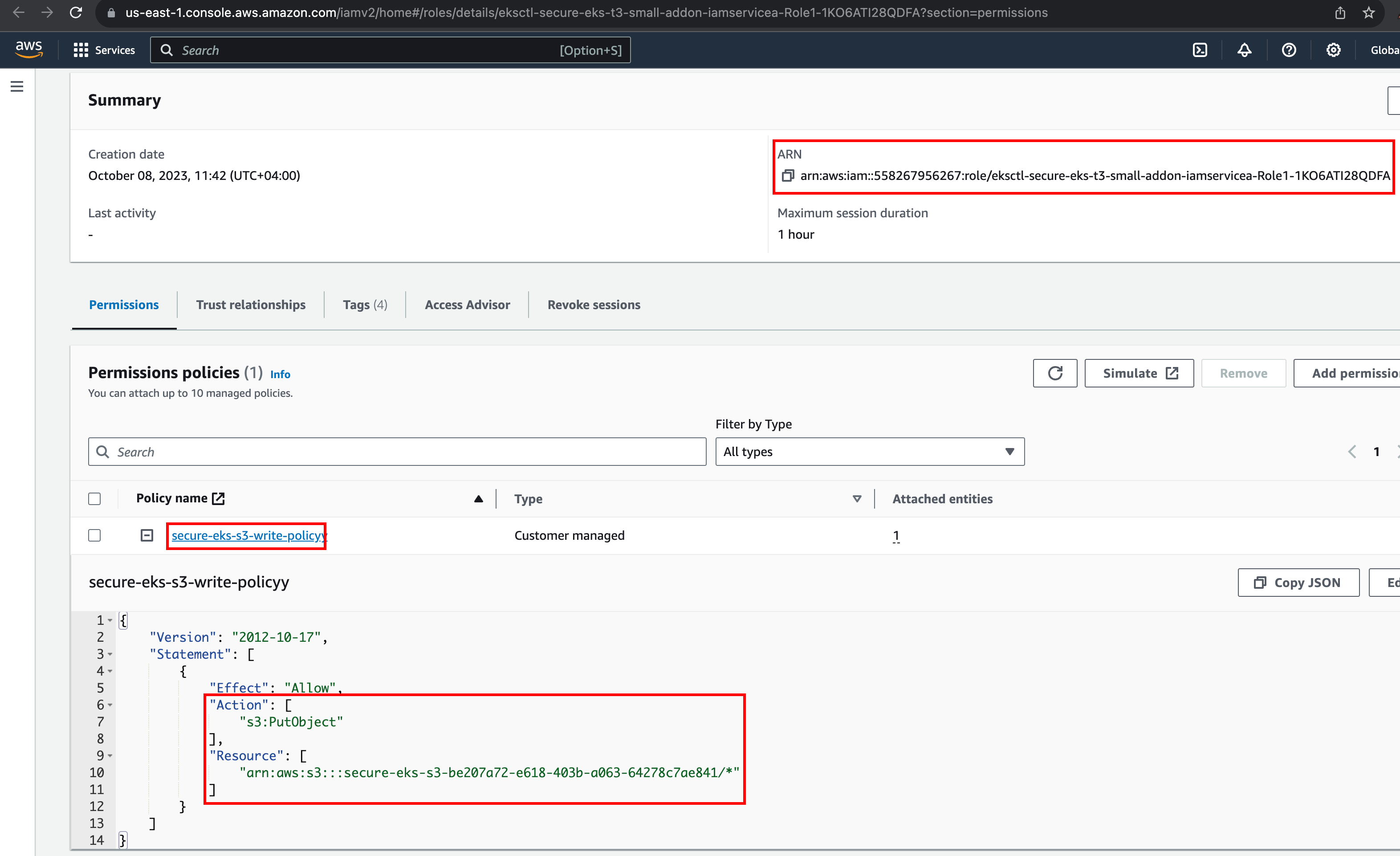
Now, we know the service account, s3-write-service-account is linked to IAM role that has permission to upload data to a specific s3 bucket.
Examine service account
Let's enumerate the service account for more information.
kubectl get sa $eks_service_account -oyaml
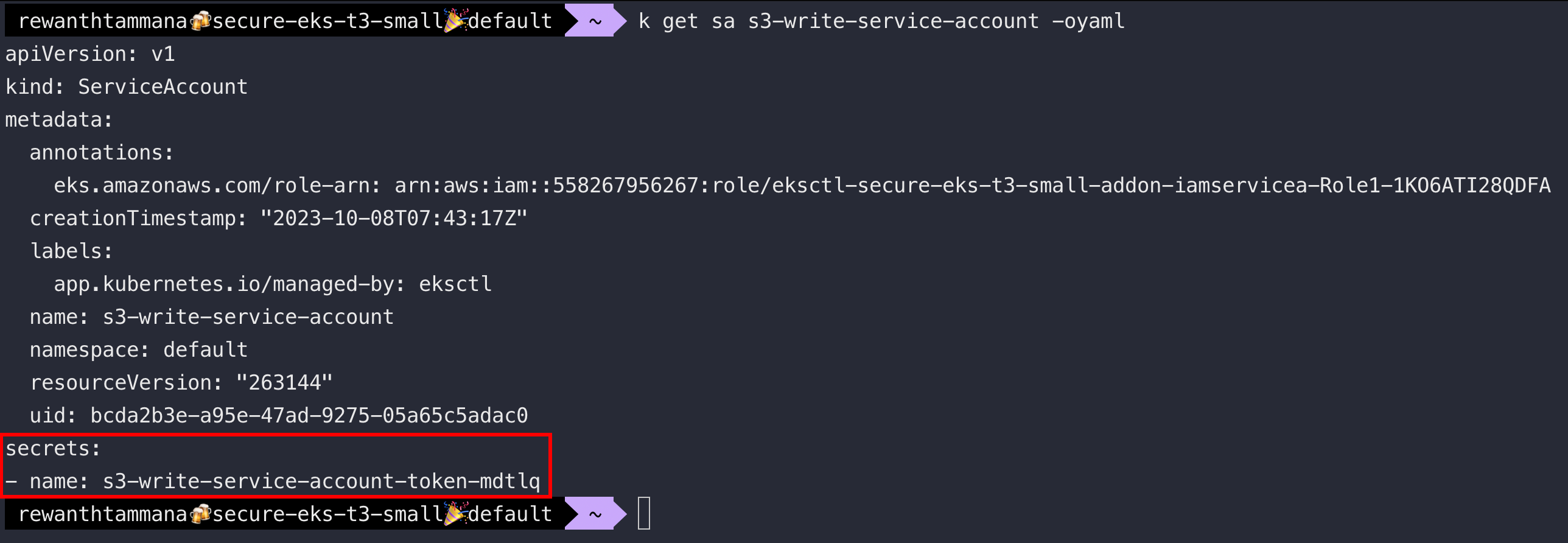
Examine secrets associated with the service account
Get the contents of the secret associated with the service account
sa_secret_name=$(kubectl get sa $eks_service_account -ojson | jq -r '.secrets[0].name')
kubectl get secrets $sa_secret_name -oyaml
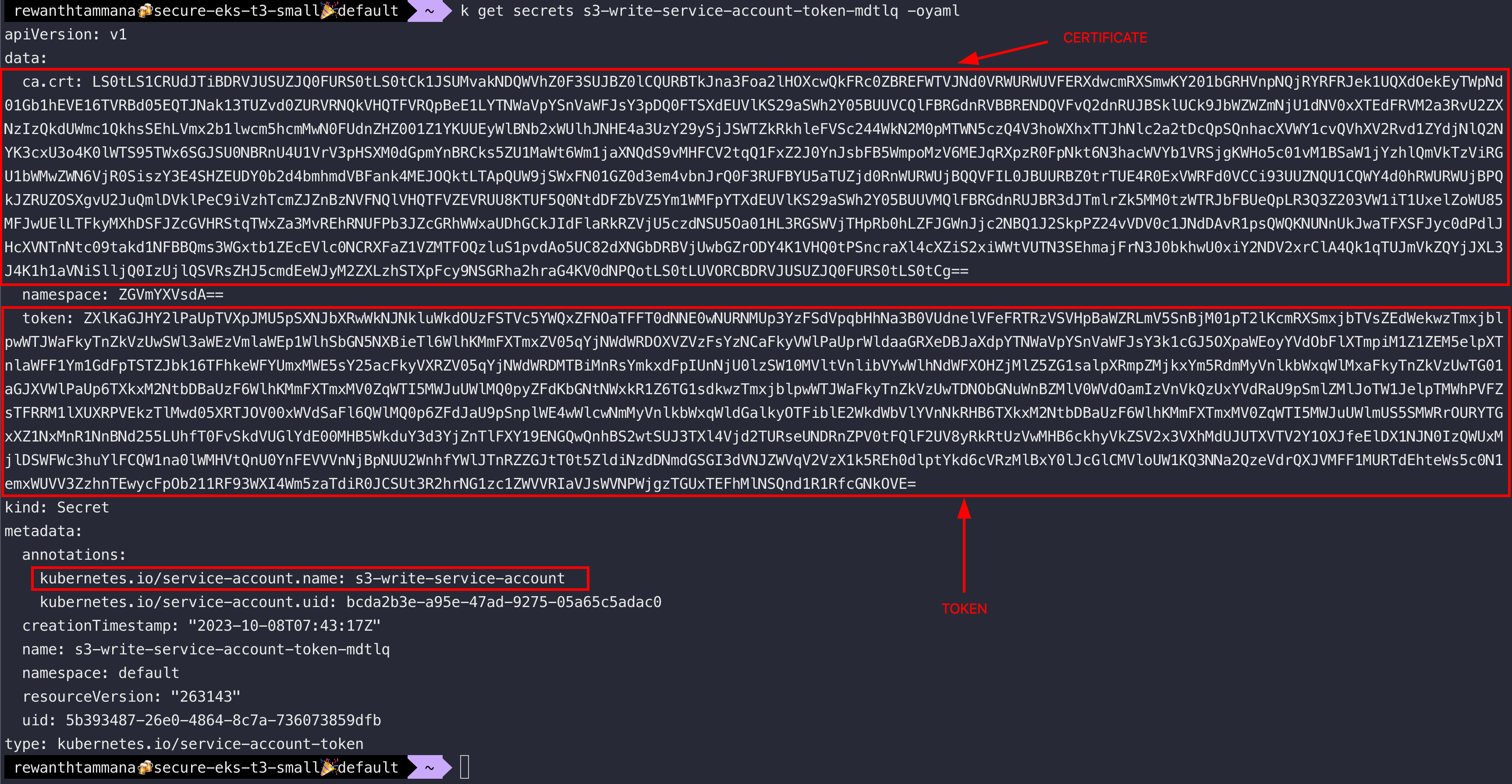
Examine X.509 ca.crt in the secret associated with the service account
In the above image, we can see the ca.crt certificate. Let's decode the certificate to view information like expiry, issuer, etc.
kubectl get secret $sa_secret_name -o json | jq -r '.data."ca.crt"' | base64 -d
kubectl get secret $sa_secret_name -o json | jq -r '.data."ca.crt"' | base64 -d > certificate.pem
Check the subject & issuer of the certificate
openssl x509 -in certificate.pem -subject -issuer -noout

Check the expiry of the certificate
openssl x509 -in certificate.pem -dates -noout

Examine the token in the secret associated with the service account
kubectl get secret $sa_secret_name -o json | jq -r '.data."token"' | base64 -d

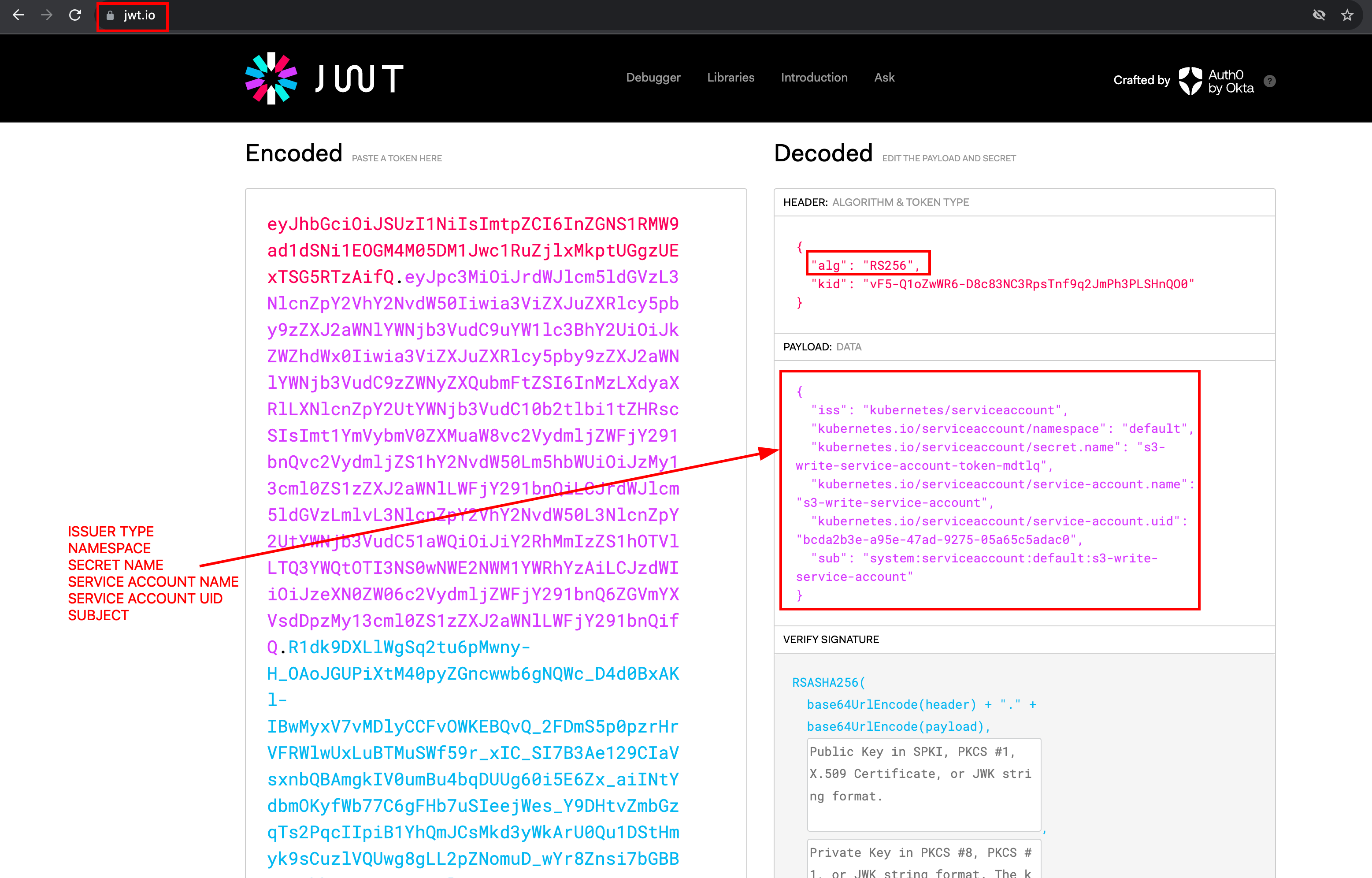
Examine the JWT token in jwt.io
Copy the token from the above step, visit jwt.io & paste it there. As you can see below, the token consists of a lot of information like issuer, namespace, secret name, service account name, etc. If you try to change any of it, the token gets invalidated.
Cleanup
# From previous sections, if you missed there
aws iam detach-user-policy --user-name $iam_user --policy-arn $policy_arn
aws iam detach-role-policy --role-name $eks_worker_node_role_name --policy-arn $policy_arn
aws iam delete-access-key --access-key-id $access_key --user $iam_user
aws iam delete-user --user-name $iam_user
# Actual cleanup
aws iam delete-policy --policy-arn $policy_arn
aws s3 rm s3://$bucket_name --recursive
aws s3 rb s3://$bucket_name
eksctl delete iamserviceaccount --name $eks_service_account --namespace default --cluster $cluster_name
eksctl delete cluster --name $cluster_name
Conclusion
To conclude, securing access control within Amazon EKS, especially when interacting with other AWS services is a meticulous approach to safeguard against unauthorized access and potential breaches. Through the exploration of various methods in this blog - from embedding IAM user credentials and assigning permissions to EKS worker nodes to the more refined and secure method using IAM Roles for Service Accounts (IRSA) - we've traversed through the landscape of EKS security.
IRSA stands out in terms of security and manageability, providing a mechanism that adheres to the principle of least privilege by assigning AWS permissions to pods, not nodes, thereby reducing the attack surface. It leverages the existing IAM OpenID Connect (OIDC) provider, ensuring a secure and auditable way to utilize AWS services directly from Kubernetes workloads.
This is not the end. Security is an ever-evolving domain & as technologies advance, so do the methodologies to exploit them.