




Table of contents
- GSOC 2017 with Nmap Security Scanner
- Hitting it off with Nmap
- Application period coding
- Official coding starts
- $ autocomplete feature for Nmap
- $ colored output for Nmap
- $ refactoring http-enum script
- $ added missing ip protocols to netutil.cc
- $ fixed issues related to cve-2014–3704 nse script
- $ enhancement made to cve-2014–3704 nse script
- $ wrote script for OpenWebNet protocol discovery
- $ removed redundant parsing functions by making enhancements
- $ developed punycode and idna libraries for nmap
- $ ncat enhancement - limit data using a delimiter
- $ script to fetch smb enum services from remote windows machine
- My GSOC codebase
- Things I learned through GSOC
GSOC 2017 with Nmap Security Scanner
Before we go any further, I thank each and every one who helped me in my way to achieving this. But for this document, I would like to limit them to my mentors Daniel Miller and Fyodor from Nmap for choosing me over several other applicants from all over the globe and for guiding me through the whole process, providing me invaluable resources at times of need and for being so supportive throughout my internship.
This article is divided into the following sub-sections.
My GSOC codebase.(Open this to directly access my contributions list)
Hitting it off with Nmap
It was in March 2017, I was told by one of my seniors about Google Summer of Code. I’m a penetration tester and security enthusiast (Web application security). So, without any delay, I started to see the list of organizations that work on security. There were only a total of 6 organizations and 5 of them caught my interest. They were Metasploit, Nmap, Tor, Honeypot, and Radare2. I thought of applying for at least 3 of them and started to do my research on each of them. After a day or two, my inner soul started saying, “You were using Nmap for the past 2 years, and it's now the time for you to show tribute to Nmap.” Without any second thought, I made up my mind to contribute to Nmap leaving all the other options behind.
Application period coding
I realized that I’m far away from my peers in terms of knowledge of the Nmap codebase and other things related to Nmap. Initially, I was a bit worried when I went over to the IRC channel(#Nmap) and found that many of them started their GSOC preparation in Dec’16 and I just started 10–15 days before the deadline. Nmap has its Scripting Engine known as NSE(Nmap Scripting Engine) for writing the scripts which are written in LUA. I never heard of this language before and on top of that I was left with very few days, still, I didn’t lose hope and since I’m a quick learner I was able to learn the language faster than anyone can. But just going through a pair of tutorial websites quickly doesn’t mean you are good with the language. So, to convince myself that I’m good at LUA, I developed a small project in LUA within a day. My LUA project automatically converts your Mozilla browser into a hacker tool kit by installing all the required add-ons.
Once I was familiar with LUA, I started to read the Nmap codebase. Nmap isn’t a single tool by itself. It has several other tools like Ncat, Nping, Ndiff, and Zenmap. One can contribute to any of these 5 tools through GSOC.
The Nmap developers on the IRC channel were very helpful. Once I found myself comfortable with the codebase I checked the issues page and picked an issue that matched my interest and I made my first PR. Later on, I felt that going only through the Github Issue Tracker will not help me to write great scripts. Since I’m familiar with Nmap usage, I knew the pros and cons of the available scripts. While I was doing my pentest during my internship, I needed a few scripts and those were missing in Nmap. I felt like implementing them would help other hackers during their pentests. This way I started to contribute to Nmap.
A few of my PRs were merged with Nmap very quickly. Yayyy…. felt very happy from the inside since I made Nmap better. This incident increased my respect towards Open Source and Nmap.
I started being active on the IRC channels and started making PRs on Github. I submitted my GSOC application two minutes before the deadline. Ufff….. felt like I was just re-born because Google doesn’t extend the deadline at any cost.
The results were compiled in a month, in the meanwhile I got myself familiar with Nmap completely and started contributing. In that one month, I got invaluable help from the Open Source community and Nmap developers which improved my coding abilities and familiarity with the Nmap codebase.
To be frank, I forgot that I applied for GSOC and I was immersed in contributing to Nmap I felt proud from the inside since I was able to help other hackers by improving Nmap source code. I was submerged in contributing to Nmap, I got a call from my senior at around 23:00 on May 4 saying I got selected into Nmap. Hurrah…..!! I was on cloud9 since I got the chance to work with Nmap through Google.
Official coding starts
Me above, screwed up with decoding SMB responses (Binary data).
I got myself active on GSOC’17 Whatsapp groups, Facebook groups, Telegram channels, Slack channels, IRCs, and so on. I got a chance to meet the best talent from all over the world. I now have connections all over the globe.
I got some resources from my mentor which I had to go through before I started actual coding. Since I was anxious, without asking my mentor’s permission I took the chance to work on the ideas I submitted in my GSOC proposal which I later on found was one of the biggest mistakes I had done. Read the next two sections to know why.
$ autocomplete feature for Nmap
Previously, all the developers have to type the commands completely to run their scripts. There are hundreds of scripts and each script has tens of arguments that no one can ever master. So, what happened was every hacker had to check the script file or documentation for using Nmap. I felt like it would be cool if we can provide a feature that can autocomplete the args upon double-tapping [TAB]. I noticed that my mentor has a private repo that provides this functionality but it fails to autocomplete the inner arguments that a script expects the user to provide. So, I thought adding that feature would be cool and I started coding it right away without his permission.
I made a PR #4 which closed issue #1 as well in the private repo.
$ colored output for Nmap

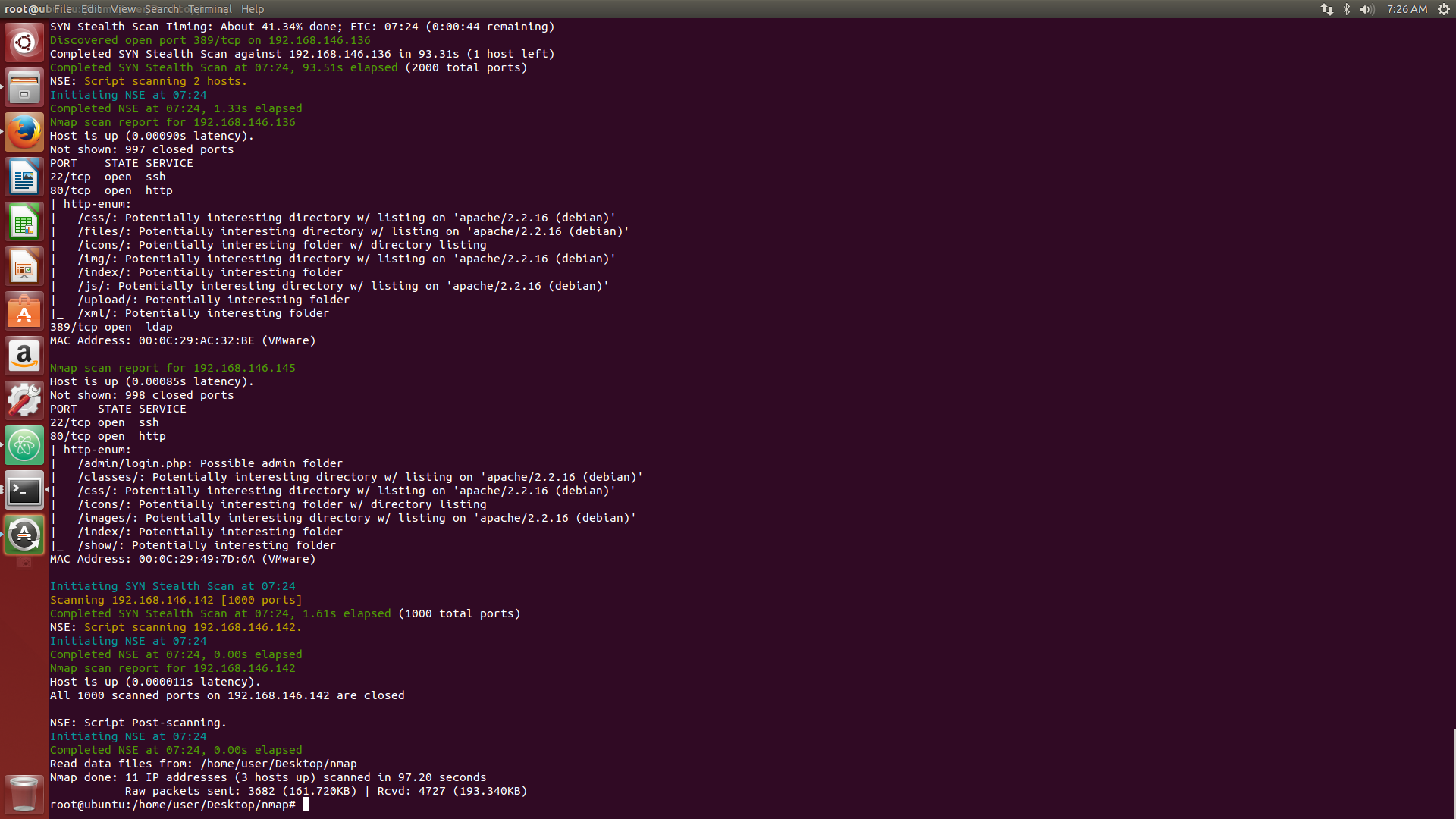
Screenshots of colored output for easy debugging purposes.
There are several options in Nmap for debugging purposes. But these debugging messages can’t be easily identified by an n00b. So, enabling this feature will increase user readability by making it easier to examine the detailed output along with debugging info.
I was very happy thinking that both the above PRs will be merged with the Nmap master branch. But sadly, both of them were turned down by my mentor, saying that this autocomplete feature and colored output will work great on Linux(bash) only and might fail on other shells like zsh, ksh, and so on. Most importantly both the above-mentioned features will not work on Windows due to lack of support. I felt very bad that I should have discussed implementing these ideas with my mentor beforehand. So, these PRs were rejected from being merged into the master branch but can be maintained in a private repo which I’m planning to release soon.
Until now I was trying to make enhancements that would help an n00b hacker but then I felt like making something useful for everyone.
$ refactoring http-enum script
The http-enum script is structured in a very old fashion. I had discussions with my mentor for more than 2 weeks regarding the changes to be made. I created a report which explains the shortcomings, new features, and improvements that can be made to optimize the script.
Report is available on Google docs,
Since we were hit with some other important tasks to complete and issues on the tracker were increasing rapidly, we thought of continuing this enhancement later on.
$ added missing ip protocols to netutil.cc
Some important IP protocols were missing from the list in netutil.cc which is being widely used. I added the important, missing protocols to the existing file. Nmap already has a mapping of protocol numbers to names, based on IANA’s assignment registry, namely the_nmap-protocols_file.
Merged proto2ascii_case and nexthdrtoa functions which return protocol name. Removed proto2ascii_lowercase function by writing a modular code for one of the existing functions.
I wrote a shell script to generate the code from the nmap-protocols file. This will be more efficient than reading and parsing the file at run time and will also make libnetutil not dependent on an external file at run time. This is important for things like Ncat and Nping that are not usually packaged with the nmap-protocols file.
$ fixed issues related to cve-2014–3704 nse script
There was issue #902 related to the malfunctioning of the cve2014–3704 script. That was a very typical issue. When this script was executed against a vulnerable server, a false output was generated. I tried exploiting the vulnerable server using Metasploit, and it was successful but when I tried to exploit it using the Nmap script there was a failure. I compared the code of Metasploit and Nmap scripts and both looked the same.
I thought there might be an issue with the way the packets were sent by the POST request in Nmap. I started to intercept the packets of both Metasploit and Nmap separately while exploiting the server using Wireshark. I observed that Nmap packets were crafted in a different format compared to Metasploit. I tried very hard for one complete week trying to figure out why the post data sent by both tools are different. After a week, I got a hacker on the Metasploit IRC channel to answer my question and I resolved the issue by sending the request.
Later on, I found that Drupal is having two login pages and only one of them is vulnerable both the URLs are different by just a single character and I felt bad that I should have observed that in the first place. I changed the endpoints of the target server in Nmap and everything was in place.
$ enhancement made to cve-2014–3704 nse script
After we attack the server, we have to check for traces of compromised instances but this is not properly done by the existing Nmap script. I don’t say it's entirely wrong but it just doesn’t work in all cases. For example, if the vulnerable website is present in Spanish or French then the existing script cannot return the correct output regarding the vulnerability. I added new conditions which check for multiple traces of compromise and then confirm the vulnerability.
$ wrote script for OpenWebNet protocol discovery
OpenWebNet Protocol is a communications protocol developed by Bticino since 2000. This protocol is mainly used for Home Automation purposes. This protocol is widely used yet good documentation is scarce for its usage. Only 2 websites are existing, which helped me in writing this script.
This new script can get information like IP Address, Net Mask, MAC address, Device Type, Firmware Version, Server Uptime, Date and Time, Kernel Version, and Distribution Version from the target. Apart from that, it can retrieve the number of automated devices, number of lights, number of burglar alarms, number of heating devices, and so on.
So, it will be a very useful script during the enumeration of home automated appliances as it is capable of fetching so many details from the target.
$ removed redundant parsing functions by making enhancements
Previously two functions from two different libraries were used for parsing the websites. Each of the functions had some extra functionality wrt others but shared code to some extent. I combined them into one function. This particular commit is a good cleanup of redundant code.
$ developed punycode and idna libraries for nmap
The existing Nmap crawler can send requests to domain names only in English.
If you try to crawl websites like “http://點看.com”_or “_http://योगा.भारत” you get an error saying the URL cannot be decoded.
I created Punycode and IDNA libraries with functions that let you encode and decode this kind of stuff. For example,
“http://點看.com” gets decoded into “xn — c1yn36f.com”.
“http://योगा.भारत” gets decodes into“http://xn--31b1c3b9b.xn--h2brj9c”.
Crawlers can now crawl the website by using the decoded URLs.
Developing these libraries had been a very challenging part. I never had the habit of reading technical papers from the first line to the bottom line. I had to read the papers thoroughly to write proper functions.
Completing this task requires high dedication because I had to read papers like UTS #46, RFC 3490, RFC 3491, RFC 3492, RFC 3493, TR#46, TR #9 and then analyze the data provided in all the above technical papers and then create the respective functions.
The real part comes here, I completely coded as mentioned in the technical standards and the code doesn’t work properly as expected. All cases were successful except one or two and then comes the highest level of depression. I didn’t have the balls to find the bug in the code because I wasn’t ready to go through 1500 lines of code, I had to go through the research papers again and I had to cross-check the code with the procedure as mentioned in the papers. Finally, after so much struggle I successfully developed the libraries.
At this point, I was fatigued working only on web-related stuff and felt like needing a change of pace. I thought of working on something which has nothing to do with the web and the following are my achievements in other parts of Nmap.
$ ncat enhancement - limit data using a delimiter
Ncat is a reimplementation of the currently splintered and reasonably unmaintained Netcat family. Ncat can act as either a client or server, using TCP or UDP over IPv4 or IPv6. SSL support is provided for both the client and server modes.
Till now I was working on LUA since the start of the GSOC and for the first time, I was hit with the idea of working with something different apart from Web and LUA. This enhancement was purely implemented in the C language.
This will be a good enhancement to the existing Ncat once the PR gets merged. Functions were added to accept delimiter as a parameter through the command line for delimiting the data before sending it.
At this stage I was like, my GSOC is about to be complete and I haven’t done anything new. I was just getting better at what I already knew. I wanted to learn and contribute more. I wanted to work on something totally new to me.
I selected to work on Windows SMB-related stuff. I didn’t even know what SMB meant until this point. I requested my mentor to allow me to work on this new area. I was left with only 10 days before I started to work on SMB.
$ script to fetch smb enum services from remote windows machine
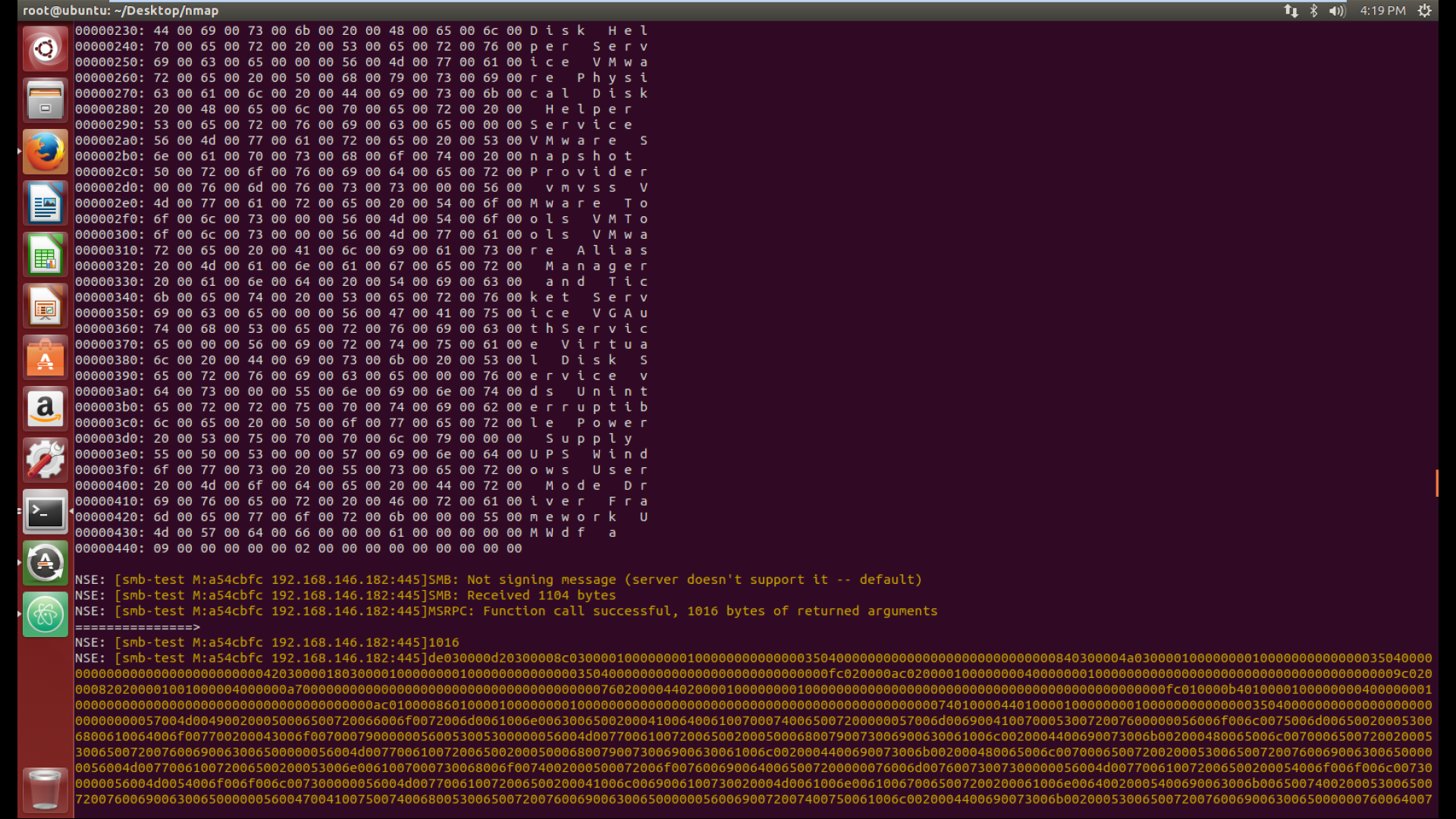
Random capture of response sent by Windows
SMB protocol is used by Windows. I had written a script that fetches the list of services running on a remote windows system along with their service status message. This has been the most challenging part of my entire GSOC stage.
I had less than 2 weeks to complete this task and I just started learning the definitions of SMB, CIFS, and so on. Once I was done with understanding the definitions, I tried to write the code. But I wasn’t familiar at all with protocols like SMB, DCERPC, SVCCTL, and so on. We can’t send a GET/POST request directly as we do on protocols like HTTP/HTTPS. It's a new game.
I found software created by windows to list the services, psservices.exe. I intercepted the packets sent by psservices.exe. I thought I could easily replicate the requests being sent based on this data.
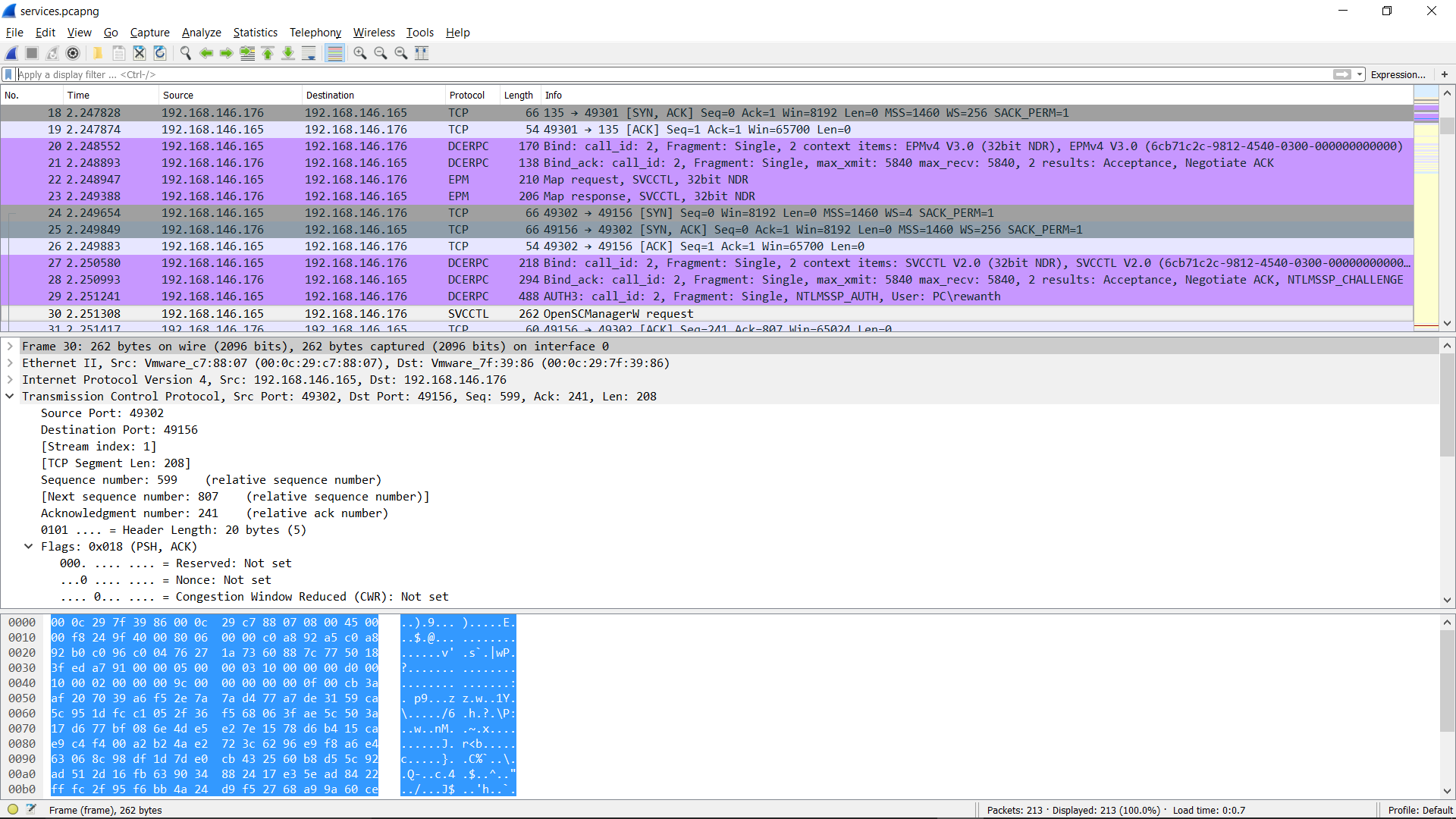
After seeing the capture I was like WTF is going on? I understood how the requests were being sent but I didn’t know how to code them. I got some useful resources from my mentor, then I figured out a way to establish the connection. Finally, wow.. I made the connection and the response looked something like this.
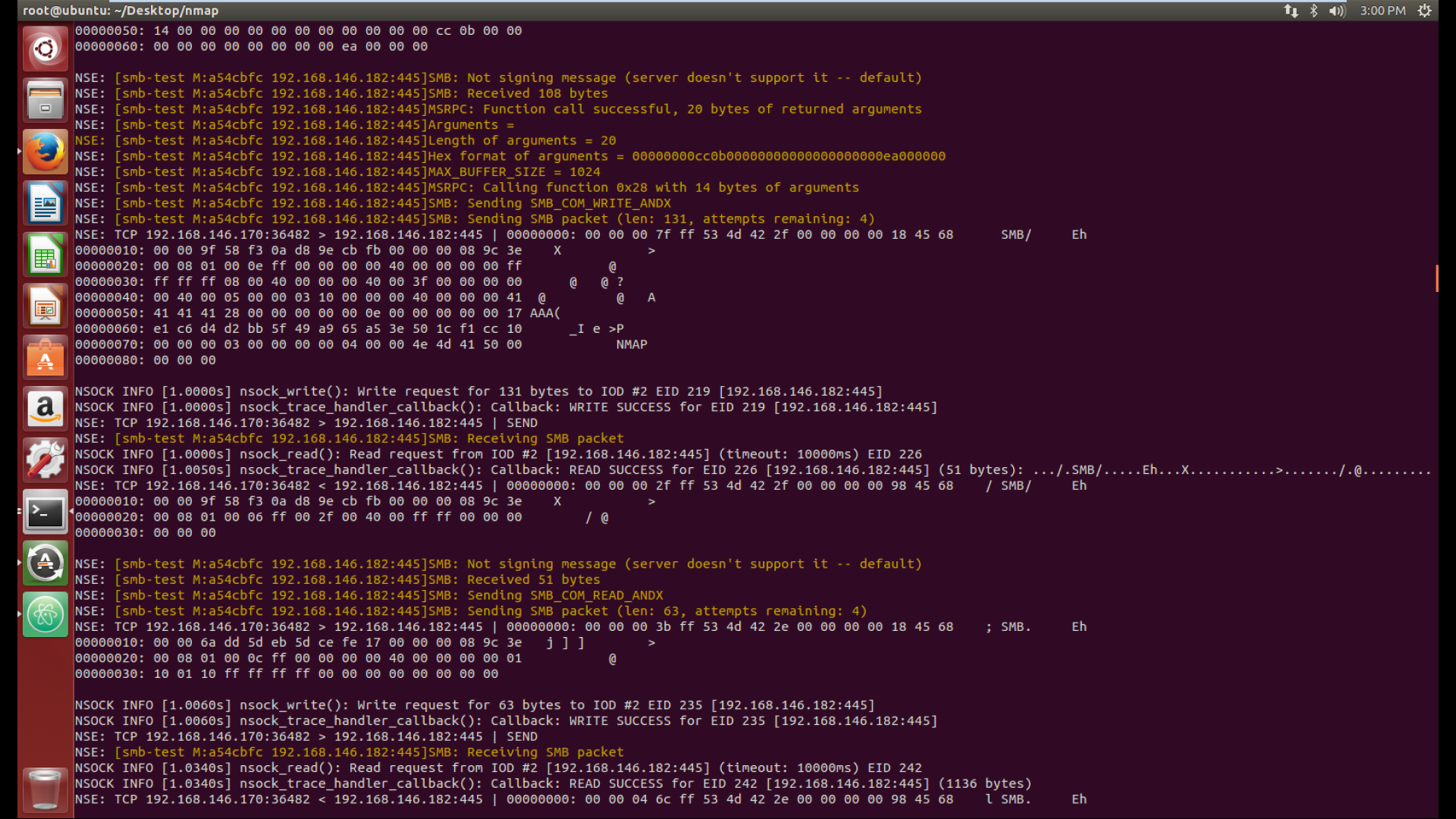
Debugging output which shows a part of the request and response sent to the server

Piece of response data received from the Windows server after making a svcctl request
I was so happy when I got the response from the server and I thought its almost done.
The response is binary data and unmarshalling or decoding the binary data was a very tricky and challenging task during my whole GSOC period.
After a long struggle for two days, the binary data decoded was unmarshalled and it displayed all the services with their service name, display name, and service status respectively.
Taking up this very challenging task with a narrow deadline gave me immense pleasure of participating in GSOC and I did learn many new things related to Windows protocol and decoding binary data.
My GSOC codebase
This section contains the links to the work I have done so far through GSOC.
The below data is taken on Sep 28, 2017.
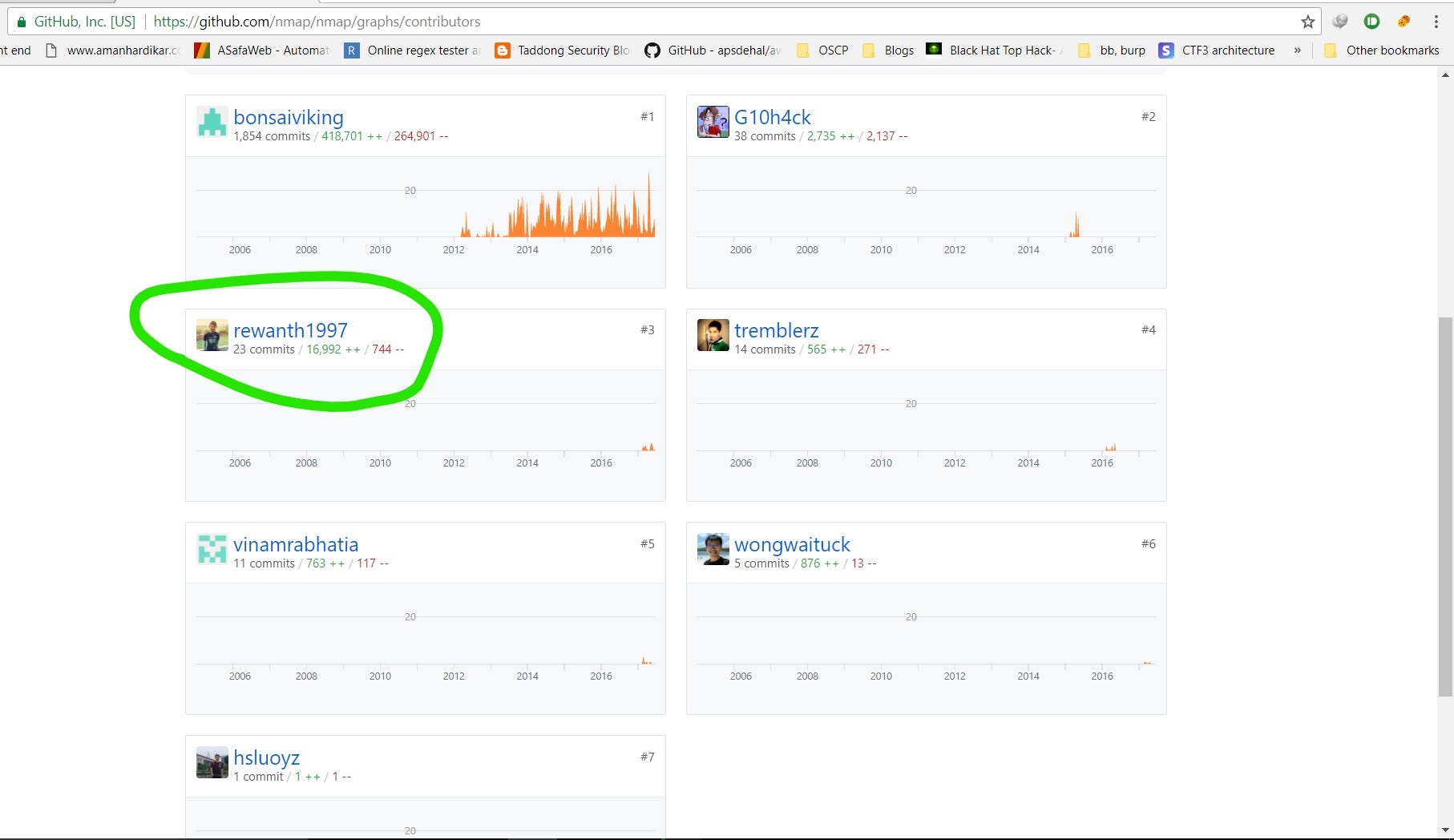
Merged commits: Total 23
Opened PRs: Total 12
https://github.com/nmap/nmap/pulls/rewanthtammana
My Closed PRs: Total 21
https://github.com/nmap/nmap/pulls?q=is%3Aclosed+is%3Apr+author%3Arewanthtammana+
Things I learned through GSOC
Learned the kind of background work needed to be done before starting to write the main code.
Collaborate with highly experienced people remotely.
Breaking the code into components at each stage. In other words, learned to write modular code effectively.
Effectively reading technical and research papers.
Techniques to be followed while refactoring existing code.
Writing scalable code. Experience with openwebnet-discovery protocol script taught this point very well.
Improved my exploitation script writing skills.
Quickly switch the tasks over and over with ease.
Gained knowledge of the SMB protocol and unmarshalling hexdump.
Analyzing the transfer of packets over Wireshark to find the errors.
Networking.
Don’t dive into new areas directly without any prior knowledge.
Finally, a quote from_The Pragmatic Programmer_book that inspired me -
“Writing code that writes code” differentiates the best from rest and I did this throughout my internship period ;)